Tuesday, December 19, 2006
Wednesday, November 08, 2006
Character Set Encoding Detection -- Part 1
Character set encoding detection becomes necessary when you starts working on processing non-English text.
I started working on south-east Asian languages a year back and I had to port some code. This particular code was working fine for English text and never gave any problems from some European non-English languages.
But when I started on working on SEA languages, I knew before starting that encoding issues will make our life hell and really it did.
Most of the softwares were just supporting English in olden days and that lead to common myth of 1byte=1char.
It takes time to digest things like characters bigger then one byte and character stream with characters of variable lengths.
Then comes the issue of which byte sequence is which character. Several countries follow different encodings, if one just gets some text as a stream of bytes and have no idea about the encoding, then there is small chance that this text will be processed correctly.
Character Set and Character encoding are the two generally interchangeably used concepts but sometimes they mean different things.
Character Set: Just a collection of characters
eg. Kannadda characters, Devanagri Characters, Japanese Characters, English alphabets
Character Encoding: Mapping a character from a character set to a numerical value.
eg. UTF-8, UTF-16, EUC-JP, EUC-KR, ISO-8859-1 to 7, ISO-2022-JP
European languages have less characters which can be fit in single byte space and so most of the European languages use ISO-8859-[1-7] character encoding.
But SEA languages, they are commonly referred as CJKV (Chines,Japanese, Korean and Vietnamese)
Best Reference for CJKV
And there are attempts made to standardize the character set, encodings
1. Unicode
2. Wikipedia Unicode link
Its very clear that different publishers have their personal choices in using different character encoding. Actually most of them are not aware of it. They just give out in default working encoding.
Now when somebody browses or crawls your page, he need to know the encoding of the text sent by you to read or programmatically process it properly. Here comes the problem of unknown encoding.
When browser or your program should do when it faces such issue. Most browser tries to detect the encoding and use. Detecting the encoding is not exact science but it works well for most of the pages.
In simple words this detection is done by checking the occurrence of certain patterns in the byte stream.
The detector which mozilla provides works better if you set the detector to detect encodings common to your language.
-----------
References
1. http://www.mozilla.org/projects/intl/chardet.html
2. http://sourceforge.net/projects/icu/
I started working on south-east Asian languages a year back and I had to port some code. This particular code was working fine for English text and never gave any problems from some European non-English languages.
But when I started on working on SEA languages, I knew before starting that encoding issues will make our life hell and really it did.
Most of the softwares were just supporting English in olden days and that lead to common myth of 1byte=1char.
It takes time to digest things like characters bigger then one byte and character stream with characters of variable lengths.
Then comes the issue of which byte sequence is which character. Several countries follow different encodings, if one just gets some text as a stream of bytes and have no idea about the encoding, then there is small chance that this text will be processed correctly.
Character Set and Character encoding are the two generally interchangeably used concepts but sometimes they mean different things.
Character Set: Just a collection of characters
eg. Kannadda characters, Devanagri Characters, Japanese Characters, English alphabets
Character Encoding: Mapping a character from a character set to a numerical value.
eg. UTF-8, UTF-16, EUC-JP, EUC-KR, ISO-8859-1 to 7, ISO-2022-JP
European languages have less characters which can be fit in single byte space and so most of the European languages use ISO-8859-[1-7] character encoding.
But SEA languages, they are commonly referred as CJKV (Chines,Japanese, Korean and Vietnamese)
Best Reference for CJKV
And there are attempts made to standardize the character set, encodings
1. Unicode
2. Wikipedia Unicode link
Its very clear that different publishers have their personal choices in using different character encoding. Actually most of them are not aware of it. They just give out in default working encoding.
Now when somebody browses or crawls your page, he need to know the encoding of the text sent by you to read or programmatically process it properly. Here comes the problem of unknown encoding.
When browser or your program should do when it faces such issue. Most browser tries to detect the encoding and use. Detecting the encoding is not exact science but it works well for most of the pages.
In simple words this detection is done by checking the occurrence of certain patterns in the byte stream.
The detector which mozilla provides works better if you set the detector to detect encodings common to your language.
-----------
References
1. http://www.mozilla.org/projects/intl/chardet.html
2. http://sourceforge.net/projects/icu/
Sudoku Solver in C++ and Lisp
These are weekend hacks and may be inefficient, if you see any possible improvement
leave a comment.
C++ code.
Following lisp code is using functional style of programming. And I wrote this when I was re-starting the lisp.
So most code is using car,cdr,cons, if ,quote and some of the functions are inefficient.
Lisp Code
leave a comment.
C++ code.
Following lisp code is using functional style of programming. And I wrote this when I was re-starting the lisp.
So most code is using car,cdr,cons, if ,quote and some of the functions are inefficient.
Lisp Code
Friday, September 29, 2006
Lisp - Strings and Characters
Lisp has an ackward syntax for characters.
In Lisp string is a array of characters. According to HyperSpec'd defination of String
" A string is a specialized vector whose elements are of type character or a subtype of type character. When used as a type specifier for object creation, string means (vector character)."
The simple example of Lisp string are
"hello lisp"
"this post is about lisp strings and characters"
Now lets see some of the string functions
1) string-concat
This function as expected concates all the strings passes as arguments
(string-concat)
""
(string-concat "Hello")
"Hello"
(string-concat "Hello" " ")
"Hello "
(string-concat "Hello" " " "World")
"Hello World"
2)subseq
This function is general function for any kind of sequences, like list, arrays
(subseq "Hello" 2 4)
"ll"
3)stringp
This function checks if given argument is string or not
(stringp "hello")
T
(stringp '(1 2 3))
NIL
4) string-equal is a function which compares two strings with case ignored.
(string-equal "hello" "Hello")
T
(string-equal "hello" "hel")
NIL
5)reverse works on any sequnce
(reverse '(1 2 3))
(3 2 1)
(reverse "hello")
"olleh"
Characters forms string
Lets see the 3rd charcter of string "hello"
(char "hello" 3)
#\l
1) Actually each charcter is associated with a number, one can find that number by
using function char-code
(char-code #\a)
97
In this case the character code returned is ASCII, but it is code use by implementation.
(char-int #\a)
97
2) digit-char-p checks if a character passed as argument is digit or not
(digit-char-p #\a)
NIL
(digit-char-p #\9)
9
(digit-char-pa #\1)
1
4)code-char returns a character for given code
(code-char 123)
#\{
5) Some special chracters
#\Tab
#\Newline
#\Space
All of above are case-insensitive
clisp supports unicode and using function code-char one can easily get
representation of any code.
In Lisp string is a array of characters. According to HyperSpec'd defination of String
" A string is a specialized vector whose elements are of type character or a subtype of type character. When used as a type specifier for object creation, string means (vector character)."
The simple example of Lisp string are
"hello lisp"
"this post is about lisp strings and characters"
Now lets see some of the string functions
1) string-concat
This function as expected concates all the strings passes as arguments
(string-concat)
""
(string-concat "Hello")
"Hello"
(string-concat "Hello" " ")
"Hello "
(string-concat "Hello" " " "World")
"Hello World"
2)subseq
This function is general function for any kind of sequences, like list, arrays
(subseq "Hello" 2 4)
"ll"
3)stringp
This function checks if given argument is string or not
(stringp "hello")
T
(stringp '(1 2 3))
NIL
4) string-equal is a function which compares two strings with case ignored.
(string-equal "hello" "Hello")
T
(string-equal "hello" "hel")
NIL
5)reverse works on any sequnce
(reverse '(1 2 3))
(3 2 1)
(reverse "hello")
"olleh"
Characters forms string
Lets see the 3rd charcter of string "hello"
(char "hello" 3)
#\l
1) Actually each charcter is associated with a number, one can find that number by
using function char-code
(char-code #\a)
97
In this case the character code returned is ASCII, but it is code use by implementation.
(char-int #\a)
97
2) digit-char-p checks if a character passed as argument is digit or not
(digit-char-p #\a)
NIL
(digit-char-p #\9)
9
(digit-char-pa #\1)
1
4)code-char returns a character for given code
(code-char 123)
#\{
5) Some special chracters
#\Tab
#\Newline
#\Space
All of above are case-insensitive
clisp supports unicode and using function code-char one can easily get
representation of any code.
Friday, August 18, 2006
AOL search Queries -- Most Common Websites Searched
My analysis of AOL search data continued. Many people use web search to search the websites.
Following are the most frequently searched websites.
Most common links for keyword "google.com"
Following are the most frequently searched websites.
- google.com 568668
- yahoo.com 455047
- myspace.com 381046
- ebay.com 225424
- aol.com 169733
- askjeeves.com 161628
- mapquest.com 120475
- disneychannel.com 113156
- msn.com 76905
- hotmail.com 64289
- pogo.com 59658
- bankofamerica.com 34671
- chase.com 33306
- cravelyrics.com 16526
Most common links for keyword "google.com"
- http://www.google.com 348057
- http://earth.google.com 5474
- http://maps.google.com 4736
- http://images.google.com 2296
- http://news.google.com 1670
- http://www.google.co.uk 1607
- http://toolbar.google.com 1111
- http://video.google.com 707
- http://groups.google.com 637
- http://scholar.google.com 536
- http://googleblog.blogspot.com 510
- http://www.google.com.au 430
- http://www.googlecom.com 397
- http://www.google.ca 383
- http://directory.google.com 319
AOL search queries - "How" question are more popular
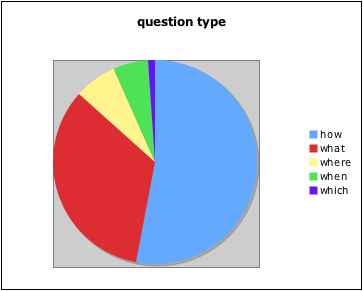
AOL Published the search data of 500k+ (657k+) "randomized" users. The intentions were good.
Because of all the privacy concerns and reports like one on NYTimes.
I just played with this data to find some general information. I tried to aggregate some data bout question people ask to search engine.
One thing is clear that people like to ask "How" very much. Out of around 21 Million uniq queries fired, around 0.16Million were questions (how what where when which). Out of these 50+% are "How" queries, see attached graph or table below.
Quetion Type count
- how 91397
- what 57659
- where 11630
- when 9600
- which 1729
Out of all these question 98424 queries generated any click. (58.43%)
All together 216007 number of clicks generated (1.28 clicks / query)
Page Clicks % age
- 1 175871 81.42
- 2 22723 10.52
- 3 7152 3.31
- 4 3062 1.42
- 5 1805 0.84
- 6 1200 0.56
Subscribe to:
Posts (Atom)